
What if you could teach an AI to drive a go-kart — not by writing a thousand "if/then" rules, but by showing it where the road is and letting it figure out the rest?
That is exactly what this project does. I take SuperTuxKart, an open-source racing game, and build three progressively more sophisticated neural networks that learn to drive by predicting where the kart should go next. No hardcoded steering logic. No GPS waypoints baked in by a human. The models look at the road, plan a trajectory, and a simple controller follows it.
Watch it drive: The CNN planner navigating a track entirely on its own. No human input after training. Just a neural network watching pixels and deciding where to go.
The code: github.com/CipherMindBob/teaching-a-tiny-ai-to-drive
The Three Architectures
I work through three models in sequence, each one removing a crutch the previous one relied on.
MLP Planner — A basic multi-layer perceptron that takes the exact coordinates of the left and right lane boundaries and predicts where to drive next. Think of this as giving the AI a perfect bird's-eye map and asking "where should I go?" It is the training wheels version: perfect information in, trajectory out.
Transformer Planner — Same perfect-information input, but now using a Perceiver-style Transformer with cross-attention. Instead of flattening everything into a single vector and hoping the MLP sorts it out, the Transformer lets each predicted waypoint individually attend to the lane boundary points that matter most. This is the same fundamental architecture behind self-driving systems at Waymo and Tesla, just scaled way down to fit on a laptop.
CNN Planner — This is where it gets real. No more perfect lane coordinates handed on a silver platter. The model receives a raw camera image — pixels, nothing else — and from this image it has to figure out where the road is AND where to drive, all at once. This is end-to-end learning: camera to steering, with everything in between learned by the network.
This progression mirrors how autonomous driving actually evolved. The industry moved away from hand-engineered perception pipelines (detect lanes → estimate depth → reproject to 3D → plan path) toward learned planners that go directly from sensor input to driving decisions. Building all three back to back makes that evolution concrete and hands-on.
Part 1: The MLP Planner — Perfect Information, Imperfect Model
What it does
The MLP receives a flattened list of waypoints describing the left and right lane boundaries and outputs three future positions for the kart. The architecture is straightforward:
class MLPPlanner(nn.Module):
def __init__(self, n_waypoints=3):
super().__init__()
self.network = nn.Sequential(
nn.Linear(2 * 10 * 2, 128), # left + right boundaries, 10 points each, x/y
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, n_waypoints * 2)
)
def forward(self, track_left, track_right, **kwargs):
x = torch.cat([track_left, track_right], dim=-1).flatten(1)
return self.network(x).view(-1, self.n_waypoints, 2)
What I learned
The MLP hits a hard ceiling fast. It trains quickly and gets the general shape of the trajectory right, but it treats all lane boundary points equally — there is no mechanism for the model to say "those three points near the upcoming curve matter more than the ones far behind me." The result is smooth enough on straightaways but imprecise through turns.
Training loss plateaued early and stayed there. The learning rate schedule decayed aggressively in the first few epochs, and once it hit near-zero around step 25, learning effectively stopped. The model simply ran out of gradient signal before it could refine its predictions.
Key insight: Flattening spatial data into a single vector destroys the geometric structure that makes the data meaningful. The MLP has no way to reason about which lane points are relevant — it just mashes everything together and hopes the weights sort it out.
Part 2: The Transformer Planner — Attention Changes Everything
What it does
The Transformer Planner keeps the same perfect-information input but replaces the MLP backbone with a cross-attention mechanism. Each predicted waypoint is a learned query. The lane boundary points are keys and values. The model attends to the boundary points that matter for each specific step of the trajectory.
class TransformerPlanner(nn.Module):
def __init__(self, n_waypoints=3, d_model=64, nhead=4, num_layers=2):
super().__init__()
self.query_embed = nn.Embedding(n_waypoints, d_model)
self.input_proj = nn.Linear(2, d_model)
decoder_layer = nn.TransformerDecoderLayer(d_model, nhead, batch_first=True)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers)
self.output_proj = nn.Linear(d_model, 2)
What I learned
Attention helps — but only up to a point. The Transformer's validation loss started rising around step 12 even as training loss continued to fall. That divergence is the textbook signature of overfitting: the model was memorizing the training tracks instead of learning generalizable driving behavior.
The learning rate schedule made it worse. A warmup followed by aggressive cosine decay drove the LR to near-zero by step 20, essentially freezing the model before it could regularize itself. With perfect input information and a relatively small dataset, the Transformer had the capacity to overfit badly and the training setup let it.
Key insight: Attention is powerful, but power without regularization is just a faster way to overfit. The Transformer needs dropout, weight decay, and a gentler learning rate schedule to stay honest.
Part 3: The CNN Planner — End-to-End Learning From Pixels
What it does
This is the hard version. The CNN receives a 96×128 pixel camera image and must output three future trajectory waypoints with no lane boundary coordinates provided. The model has to learn what a road looks like, where the edges are, and how that translates into steering — all from the image alone.
class CNNPlanner(nn.Module):
def __init__(self, n_waypoints=3):
super().__init__()
self.n_waypoints = n_waypoints
self.register_buffer("input_mean", torch.as_tensor(INPUT_MEAN))
self.register_buffer("input_std", torch.as_tensor(INPUT_STD))
self.features = nn.Sequential(
nn.Conv2d(3, 32, 5, stride=2, padding=2), nn.ReLU(),
nn.Conv2d(32, 64, 5, stride=2, padding=2), nn.ReLU(),
nn.Conv2d(64, 128, 3, stride=2, padding=1), nn.ReLU(),
nn.Conv2d(128, 128, 3, stride=2, padding=1), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
)
self.head = nn.Sequential(
nn.Flatten(),
nn.Linear(128, 256), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(256, n_waypoints * 2)
)
The convolutional layers progressively compress the 96×128 image into a 128-dimensional representation that captures the essential spatial structure of the road. The head then maps that representation to three (x, y) trajectory waypoints.
What I learned
The CNN dominated. Training loss reached 0.238 and was still declining at epoch 50. Validation loss reached 0.45 — also still declining. Neither curve had plateaued. The model had not finished learning.
The key was the learning rate schedule. A multi-step decay held the LR high (~0.001) for the first 35 epochs, then dropped it sharply — twice — in the final 15 epochs. This gave the model time to explore the loss landscape broadly before precision-tuning in the final phase. The MLP and Transformer both had their LR killed too early, which is why they stopped improving.
Key insight: End-to-end learning from raw pixels is harder to set up but produces a fundamentally more capable model. There is no intermediate representation to get wrong. The model learns exactly the features it needs for the task it is solving.
Part 4: What the Training Curves Told Me
The TensorBoard logs tell the story better than any summary table.
Training Loss
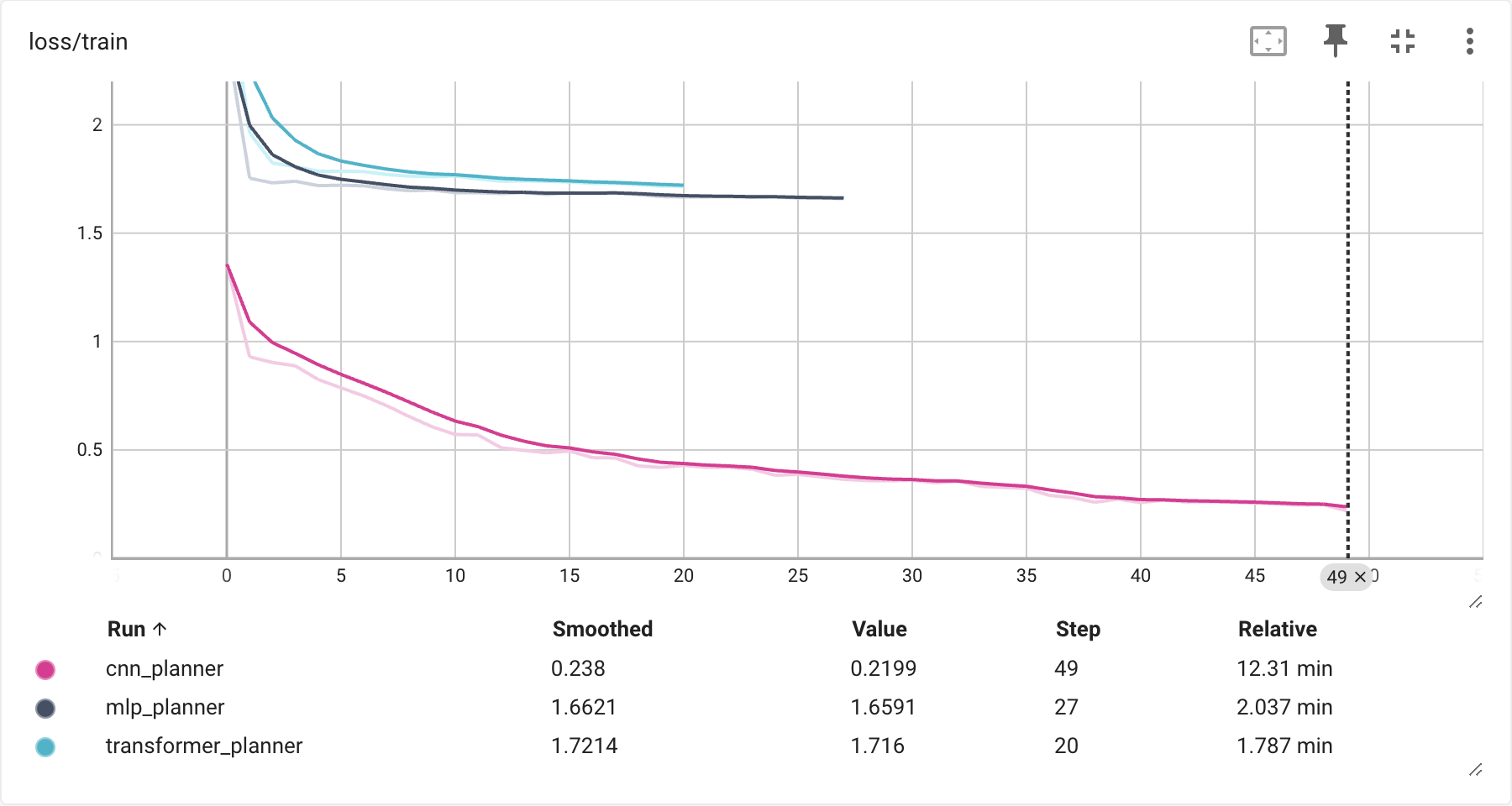
The CNN's training loss (pink) drops steadily across all 50 epochs, ending near 0.24. The MLP (dark) and Transformer (cyan) both plateau within the first 20–25 steps at roughly 1.65–1.72 — nearly ten times higher than the CNN. They did not run out of data. They ran out of gradient signal when the learning rate decayed too aggressively too early.
Validation Loss
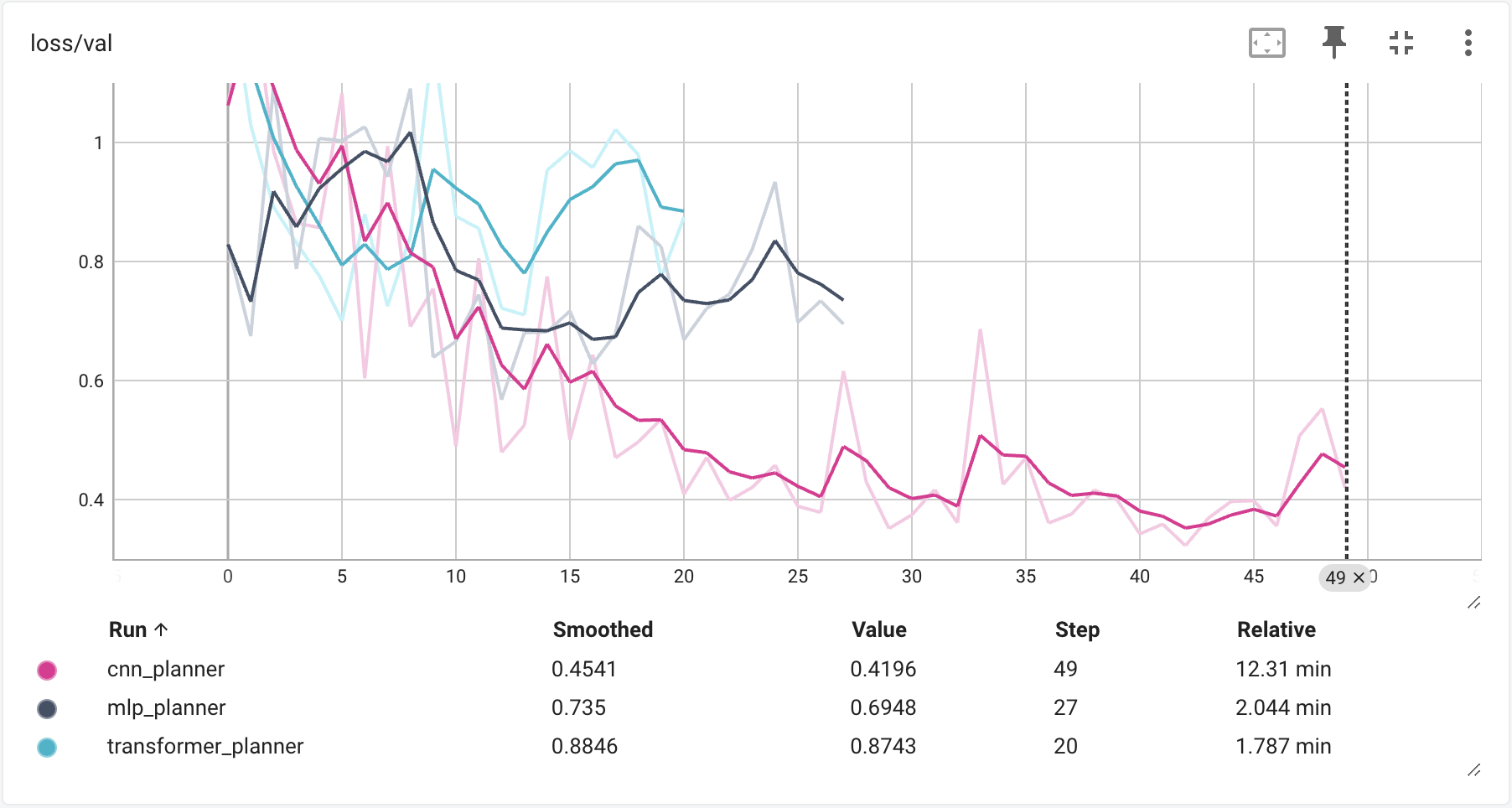
This is the most revealing chart. The CNN's validation loss tracks its training loss downward — healthy behavior, both curves moving in the same direction. The Transformer's validation loss starts rising around step 12 while training loss keeps falling. That divergence is overfitting: the model memorized the training data instead of learning to drive. The MLP stagnates at 0.73 — it stopped learning rather than overfit, which is less dramatic but equally useless.
Learning Rate Schedule
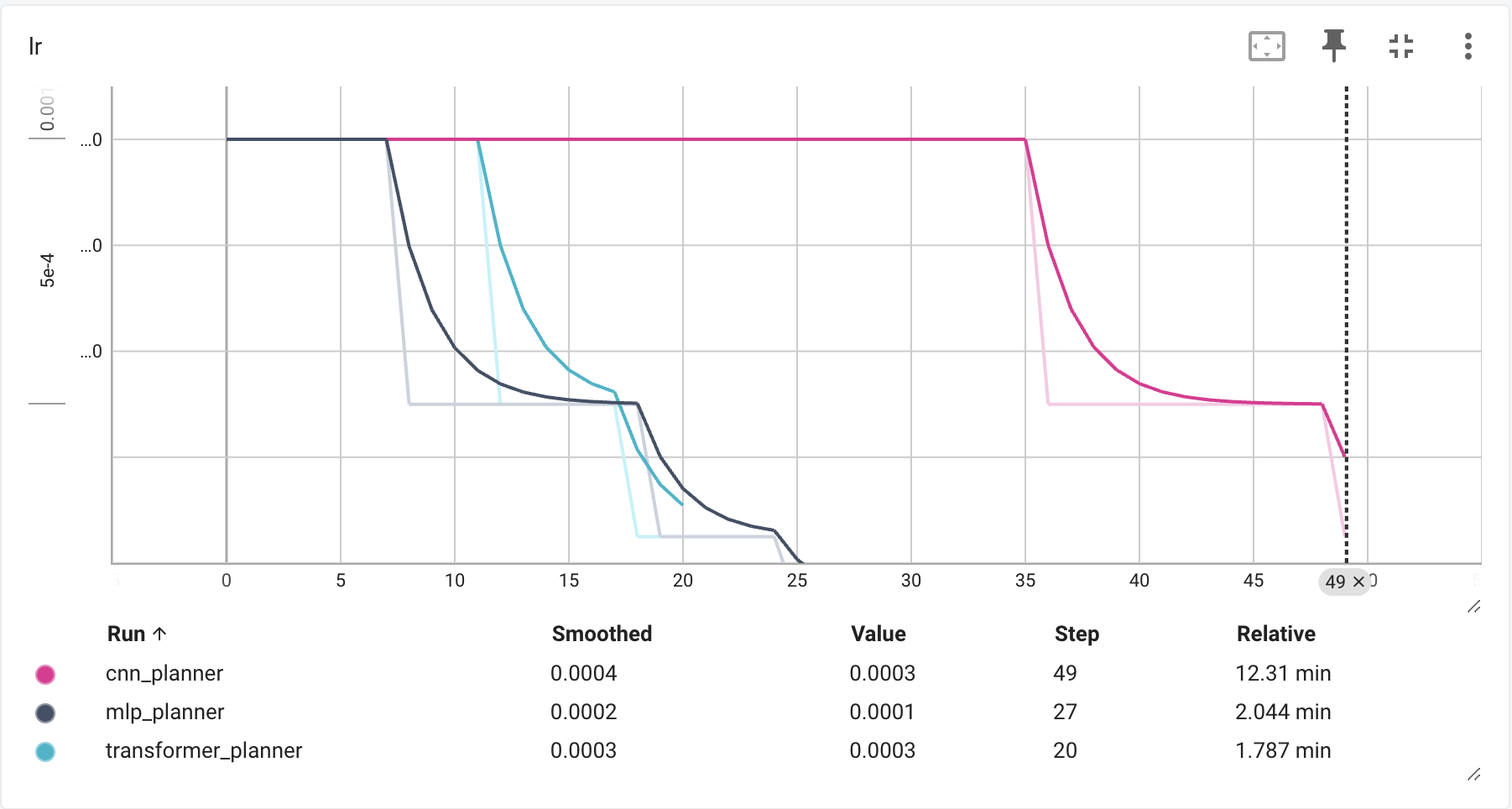
This chart explains everything. The CNN holds its learning rate constant for 35 epochs, then steps down sharply — twice. The MLP and Transformer both decay to near-zero within 25 and 20 steps respectively, then flatline. When the learning rate hits zero, the model stops updating. The CNN's schedule gave it three times as much effective training. That alone accounts for most of the performance gap.
Model Comparison
| Model | Train Loss | Val Loss | Epochs | LR Schedule | Verdict |
|---|---|---|---|---|---|
| MLP | 1.66 | 0.74 | 27 | Aggressive decay, stopped early | Undertrained |
| Transformer | 1.72 | 0.89 | 20 | Warmup + fast decay | Overfit + undertrained |
| CNN | 0.24 | 0.45 | 50 | Multi-step, held high | Clear winner |
What I Actually Learned
Three models, three completely different failure modes, and one big lesson: the architecture matters less than you think. The CNN won not just because convolutional layers are well-suited to images — it won because the training setup gave it the time and gradient signal it needed to actually learn.
The MLP and Transformer had their learning rates killed before they could converge. The Transformer had enough capacity to overfit badly once the LR decayed. The CNN had a schedule that respected how long deep learning actually takes.
You can have the right architecture and the wrong training setup and still lose to a simpler model with better hyperparameters. That is the lesson I did not expect going in.
The second lesson: end-to-end learning is underrated. The CNN had to do more work — figure out what a road looks like before it could figure out how to drive — and it still produced a model that was an order of magnitude better on training loss and visibly smoother on the actual track. There is something powerful about letting the model learn exactly what it needs rather than giving it pre-processed inputs and hoping the intermediate representation was the right one.
What I Would Do Next
- Train the CNN longer. Both loss curves were still declining at epoch 50. More compute, more improvement.
- Fix the Transformer's LR schedule. Slower decay + stronger dropout would likely close the gap significantly.
- Try a ResNet backbone. The current CNN is hand-rolled and relatively shallow. A pretrained ResNet encoder would bring in feature representations learned from millions of real images.
- Add data augmentation. Color jitter, random flips, brightness variation — the CNN would generalize better to track variations it has not seen.
References
- NVIDIA "End to End Learning for Self-Driving Cars" (2016) — arxiv.org/abs/1604.07316
- Perceiver: General Perception with Iterative Attention — arxiv.org/abs/2103.03206
- SuperTuxKart — supertuxkart.net